Zig provides an interface for memory allocators in the form of std.mem.Allocator. Some allocators implement this interface directly (see for example std.heap.PageAllocator), but you can also use it to wrap an existing allocator. This is what std.heap.debug_allocator does, for example.
The way this generally works is you create your own custom allocator struct and then write a function that takes your allocator and outputs a std.mem.Allocator, which is a struct in this format:
ptr: *anyopaque,
vtable: *const VTable,
pub const VTable = struct {
alloc: *const fn (...) ?[*]u8,
resize: *const fn (...) bool,
remap: *const fn (...) ?[*]u8,
free: *const fn (...) void,
};
(Arguments omitted here to make it easier to read.) The underlying allocator will already have such a VTable, whose functions are conveniently also available in the interface under rawAlloc, rawResize, rawRemap, rawFree.
The example of std.head.ThreadSafeAllocator is instructive:
child_allocator: Allocator,
mutex: std.Thread.Mutex = .{},
pub fn allocator(self: *ThreadSafeAllocator) Allocator {
return .{
.ptr = self,
.vtable = &.{
.alloc = alloc,
.resize = resize,
.remap = remap,
.free = free,
},
};
}
fn alloc(ctx: *anyopaque, n: usize, alignment: std.mem.Alignment, ra: usize) ?[*]u8 {
const self: *ThreadSafeAllocator = @ptrCast(@alignCast(ctx));
self.mutex.lock();
defer self.mutex.unlock();
return self.child_allocator.rawAlloc(n, alignment, ra);
}
// (...)
Other than the pointer casting this is pretty straightforward: acquire a lock, run rawAlloc() in the underlying allocator (which in turn will call alloc()), release the lock.
This interface proved useful to me while working my way through Crafting Interpreters, specifically the Garbage Collection chapter. In the book the VM is implemented in C, and memory management is implemented as a few wrappers to realloc and free (see memory.c, memory.h). Additionally there's a few macros for handling resizable arrays. Before reaching this chapter, my Zig implementation didn't have any wrappers, although I did stick to the allocator interface instead of hardcoding a particular allocator. I also didn't feel the need to implement resizable arrays since Zig's ArrayList can already handle that.
For Lox's garbage collector, we need two things: first, we need to hold a reference to the VM (including the compiler), so we can traverse the objects it allocates and perform the mark-and-sweep algorithm. We also need to keep track of how much memory it's allocating so we can decide when to perform garbage collection. Essentially it looks like this:
fn alloc(ctx: *anyopaque, n: usize, alignment: std.mem.Alignment, ra: usize) ?[*]u8 {
const self: *Self = @ptrCast(@alignCast(ctx));
if (self.shouldGC()) {
self.collectGarbage();
}
return self.child_allocator.rawAlloc(n, alignment, ra);
}
fn shouldGC(self: Self) bool {
return self.debug_stress or self.bytes_allocated > self.next_gc;
}
fn collectGarbage(self: *Self) void {
self.markRoots(self.vm);
self.markCompilerRoots(self.compiler);
self.traceReferences();
self.tableRemoveWhite(compiler.vm, &compiler.vm.strings);
self.sweep(compiler.vm);
self.next_gc = self.bytes_allocated * gc_heap_growth_factor;
}
resize() and remap() can also allocate memory, so we'll want to run collectGarbage() there as well. One note about keeping track of the allocated memory: these functions (including alloc()) don't always allocate, so we need to check the return value before updating the counter. For example, alloc():
fn alloc(ctx: *anyopaque, n: usize, alignment: std.mem.Alignment, ra: usize) ?[*]u8 {
const self: *Self = @ptrCast(@alignCast(ctx));
if (self.shouldGC()) {
self.collectGarbage();
}
const ptr = self.child_allocator.rawAlloc(n, alignment, ra);
if (ptr != null) {
self.bytes_allocated += len;
}
return ptr;
}
Another bit of nuance (which is covered in the book) is that at times we need to prevent some memory from being garbage-collected, for example if we're in the middle of a partly initialized object; in these cases the allocated memory won't be marked so it'd get swept if GC runs. The book uses a few tricks where it temporarily puts values in the stack so the memory gets marked, which I suppose is fine but I've found it more convenient to temporarily disable the GC in such situations. This works quite well in conjunction with Zig's defer; whenever I disable GC I can put a defer gc.is_disabled = false and be sure it'll be enabled again when the function returns.
A closure implementation in a compiler requires a mechanism for keeping track of values of variables that were bound in the environment surrounding the function at the moment it's declared. The values can change after the function is declared (usually by the function itself), so some form of non-local state needs to be maintained.
This was a lot of words, so here's a JavaScript example.
function newCounter() {
let i = 0;
return function inner() {
i += 1;
return i;
}
}
const c1 = newCounter();
console.log(c1()); // 1
console.log(c1()); // 2
const c2 = newCounter();
console.log(c2()); // 1
inner() accesses (and modifies) i, which is a variable declared outside inner() (we say it's a free variable in inner()). Each call to newCounter() will create a new closure with its own i.
Implementation
So how do you implement this? I only know about the Lua way, which I learned while reading Crafting Interpreters. (See also The implementation of Lua 5.0.) Free variables are stored in a structure that they call an upvalue.
When the compiler resolves a variable in a function, it first checks if it's a local variable. If not then it tries to resolve it as an upvalue, by first trying to resolve it as a local in the immediately surrounding block. If it can't then it tries to resolve it as an upvalue in the surrounding block.
So it's a recursive procedure, so resolving an upvalue might require going up an arbitrary number of blocks. However because the resolved upvalue gets added to the list of upvalues in the immediately surrounding block, it's still fast to look up at runtime.
One complication is introduced by the fact that multiple closures might refer to the same variable. For example:
function init()
local i = 0
function get()
return i
end
function set(j)
i = j
end
return get, set
end
get, set = init()
print(get()) // 0
set(5)
print(get()) // 5
Both get() and set() share the state of i. If each of them created their own upvalue this wouldn't work as they each would have their own state. The way Lua handles that is by keeping a list of all upvalues in the stack, which allows for checking for whether an upvalue has already been created before adding a new one.
What makes an upvalue different from a regular local variable is that when the environment where it's bound goes out of scope, it doesn't merely get popped off the stack. So there's also a simple mechanism for moving them from the stack to the heap when a block ends.
Lua example
From Programming in Lua:
function newCounter()
local i = 0
return function()
i = i + 1
return i
end
end
c1 = newCounter()
print(c1())
This produces the following bytecode:
main <closure.lua:0,0> (11 instructions at 0x5e0bec242a30)
0+ params, 2 slots, 1 upvalue, 0 locals, 3 constants, 1 function
1 [1] VARARGPREP 0
2 [7] CLOSURE 0 0 ; 0x5e0bec242f90
3 [1] SETTABUP 0 0 0 ; _ENV "newCounter"
4 [9] GETTABUP 0 0 0 ; _ENV "newCounter"
5 [9] CALL 0 1 2 ; 0 in 1 out
6 [9] SETTABUP 0 1 0 ; _ENV "c1"
7 [10] GETTABUP 0 0 2 ; _ENV "print"
8 [10] GETTABUP 1 0 1 ; _ENV "c1"
9 [10] CALL 1 1 0 ; 0 in all out
10 [10] CALL 0 0 1 ; all in 0 out
11 [10] RETURN 0 1 1 ; 0 out
function <closure.lua:1,7> (4 instructions at 0x5e0bec242f90)
0 params, 2 slots, 0 upvalues, 1 local, 0 constants, 1 function
1 [2] LOADI 0 0
2 [6] CLOSURE 1 0 ; 0x5e0bec2432a0
3 [6] RETURN 1 2 0k ; 1 out
4 [7] RETURN 1 1 0k ; 0 out
function <closure.lua:3,6> (7 instructions at 0x5e0bec2432a0)
0 params, 2 slots, 1 upvalue, 0 locals, 0 constants, 0 functions
1 [4] GETUPVAL 0 0 ; i
2 [4] ADDI 0 0 1
3 [4] MMBINI 0 1 6 0 ; __add
4 [4] SETUPVAL 0 0 ; i
5 [5] GETUPVAL 0 0 ; i
6 [5] RETURN1 0
7 [6] RETURN0
Note SETUPVAL and GETUPVAL. (Also note that Lua uses a register-based VM, unlike Lox.)
Is it an original concept?
The Lua 5.0 paper presents this concept as novel, but given how simple it is and given how important closures are to functional programming I wonder to which extent that's true. Perhaps the novelty comes from the design goal of being a high-level language that's also small and easy to embed, which imposes a simple implementation. I wonder how ECL does it…
Unlike C, Zig doesn't provide guarantees on the order of fields in a struct. From the language reference:
// Zig gives no guarantees about the order of fields and the size of
// the struct but the fields are guaranteed to be ABI-aligned.
This means we can't do anything like C type punning, even without taking strict aliasing into consideration (see last post). However the language does provide some facilities for navigating the structure which enable doing what Crafting Interpreters calls "struct inheritance". We have @fieldParentPtr():
const ObjString = struct {
obj: Obj,
payload: []const u8,
};
const Obj = struct {
obj_type: ObjType,
const ObjType = enum { string };
pub fn format(self: *const Obj, writer: *std.Io.Writer) !void {
switch (self.obj_type) {
.string => {
const s: *const ObjString = @fieldParentPtr("obj", self);
try writer.print("{s}", .{s.payload});
},
}
}
};
The idea here is that Obj will always be part of some larger struct (in this case I only have ObjString, but there could be others). From a pointer to an Obj we can use @fieldParentPtr() to access the address of that larger struct. We need a special construct for this because we don't know how the struct is laid out in memory so we don't know which offset the obj field in ObjString is at. (Although I suppose we could use another special construct, @offsetOf(), for this.)
We also need @alignCast() because ObjString has alignment 8 (on my machine anyway) and Obj has alignment 1, and we need to tell the compiler to increase the pointer's alignment. Compiling without it produces an error:
punning.zig:13:37: error: @fieldParentPtr increases pointer alignment
const s: *const ObjString = @fieldParentPtr("obj", self);
^~~~~~~~~~~~~~~~~~~~~~~~~~~~
punning.zig:13:37: note: '*align(1) const punning.ObjString' has alignment '1'
punning.zig:13:37: note: '*const punning.ObjString' has alignment '8'
punning.zig:13:37: note: use @alignCast to assert pointer alignment
Anyway, this is how we can pass a pointer to an Obj to a function and have it use the larger struct around it. Note that we lose a bit of type safety with this since the compiler can't guarantee that the Objs we're passing around come from structs of the right type, which is why we check obj_type first.
Here's an example:
pub fn main() !void {
const obj_string: ObjString = .{
.obj = .{ .obj_type = .string },
.payload = "hello",
};
std.debug.print("{f}\n", .{&obj_string.obj});
const obj: Obj = .{ .obj_type = .string };
std.debug.print("{f}\n", .{&obj});
}
The first print() runs fine; the second one fails with "panic: incorrect alignment".
Reading the chapter on strings in Crafting Interpreters led me into a rabbit hole about strict aliasing rules in C. I can't say I master the subject now but I learned a few things.
I started with Wikipedia's article on type punning, which was probably a bad idea as it turns out the BSD sockets example doesn't, as far as I can tell, obey strict aliasing rules. sockaddr and sockaddr_in are defined like this.
// From <sys/socket.h>
struct __attribute_struct_may_alias__ sockaddr
{
__SOCKADDR_COMMON (sa_); /* Common data: address family and length. */
char sa_data[14]; /* Address data. */
};
// From <arpa/inet.h>
/* Structure describing an Internet socket address. */
struct __attribute_struct_may_alias__ sockaddr_in
{
__SOCKADDR_COMMON (sin_);
in_port_t sin_port; /* Port number. */
struct in_addr sin_addr; /* Internet address. */
/* Pad to size of `struct sockaddr'. */
unsigned char sin_zero[sizeof (struct sockaddr)
- __SOCKADDR_COMMON_SIZE
- sizeof (in_port_t)
- sizeof (struct in_addr)];
};
The C standard says,
An object shall have its stored value accessed only by an lvalue expression that has one of
the following types:
- a type compatible with the effective type of the object,
- a qualified version of a type compatible with the effective type of the object,
- a type that is the signed or unsigned type corresponding to the effective type of the object,
- a type that is the signed or unsigned type corresponding to a qualified version of the effective type of the object,
- an aggregate or union type that includes one of the aforementioned types among its members (including, recursively, a member of a subaggregate or contained union), or
- a character type.
You might think the fifth rule applies since both structs have __SOCKADDR_COMMON and sockaddr_in has the sin_zero padding at the end so they have the same size, but as I understand it you'd actually have to include struct sockaddr inside sockaddr_in for it to apply, like:
struct sockaddr {
sa_family_t sa_family;
};
struct sockaddr_in {
struct sockaddr sa_addr;
in_port_t sin_port;
struct in_addr sin_addr;
}
This is also what Crafting Interpreters does with Obj and ObjString.
(Note also that the actual declarations of sockaddr and sockaddr_in have the may_alias attribute, which makes GCC treat this like a character type for the purposes of aliasing.)
While researching the subject I found a lot of writing about the subject, including a 2006 post by Mike Acton (of Data-Oriented Design fame). The best explanation I found was What is the Strict Aliasing Rule and Why do we care?. The GCC docs also have a good page. I also found this fun Linus email where he complains about strict aliasing and standards in general.
Zig has an error set type, which is basically a global enum: you can just go and use error.MyCustomError and the compiler will assign it a unique integer, and then if you use it anywhere else it'll translate to the same integer. You can define error sets, which can contain several different error values, for example you can do const MyError = error{A, B} and then write MyError.A (which is the same as writing error.A).
Functions can return errors, and there's some special syntax for that. A function that returns an error will have a type like MyError!u16, where MyError is an error set containing all possible error values, and u16 is the type the function returns if there's no error. This is just like Go's error, result pattern except with actual syntax. Or like Rust's Result type, except that Zig is a little less annoying about having to define the error type: very often you can just write !u16 and the compiler will infer the error type.
There's a little bit more to errors (for example you can do try just like in Rust) but as far as features this is about all you get. This leaves open the question of how to attach contextual information for the purposes of reporting. For example Go has error wrapping, and Rust has libraries like anyhow that enable you to add context to errors.
There isn't exactly a well-defined "best practice" on how to do this but a popular approach seems to be the "diagnostics" pattern. I don't know if "diagnostics" is an established term but several places in std use it (std.json, for example).
Anyway the idea is quite simple: you create a struct named Diagnostics to store contextual information, which can be for example an error message, or, for something like a parser, line/column numbers. Functions that can return the errors you're interested in will take an additional argument: a pointer to the Diagnostics struct. The caller is responsible for allocating space for the struct and keeping track of its lifetime. If the function returns an error, the caller can inspect the Diagnostics struct and react accordingly. For a very contrived example:
const Diagnostics = struct {
line_number: usize,
};
fn add(self: *Parser, next_count: u64, diagnostics: ?*Diagnostics) error.Overflow!u64 {
const sum = @addWithOverflow(self.count, next_count);
if (sum[1] != 0) {
if (diagnostics) |diag| {
diag.line_number = self.current_line_number;
}
return error.Overflow;
}
self.count = sum[0];
return self.count;
}
(You can of course add the pointer to the relevant struct, Parser in this case, so you don't need to pass it to every function.)
So it is a pretty simple idea. When I first started looking into this I was surprised that there isn't more in the language itself to support this pattern, but it makes sense that they wouldn't want to add something that incurred hidden allocations, which is kind of a core Zig principle. This pattern is probably also not unfamiliar to C programmers since this is basically the only way to have error handling beyond returning error codes. (See for example glib).
I've been programming Go on and off for the past few months and errors still confuse me. This might sound surprising since Go errors are pretty simple, but their simplicity also betrays the fact that there's no standardized way of structuring them in larger programs, which makes me endlessly confused when navigating different codebases.
There's a really good blog post from 2016 elaborating on errors. It's old though and some features have been added since then. I also figured it'd be better for me to internalize them if I wrote about them myself.
First, Go has no exceptions. Instead, functions that can error just return the error. Go doesn't have union types so instead functions just return potentially multiple values, with the error as one of the values. Error handling and Go gives this example:
func Open(name string) (file *File, err error)
error is an interface and if it's not nil, that means an error has happened and you need to handle that.
So, let's say you want to open a file, so you call Open. You check that the second value it returns is not nil. What to do then?
First, we need to consider the context. Why are you opening a file? Let's say you have a script that takes a filename from the user and tries to open it. You might get an error because there's no such file with the name provided, in which case the error will be ErrNotExist. You can check for that error (using errors.Is(err, ErrNotExist)) and tell the user that the file doesn't exist, for example. In another context, you might have a long-running program (a database, for example) and you can't keep everything in memory so you need to read files at various times. Most of the time you'll expect the files to exist. If they don't then something very wrong has happened and you need to be ready to recover from that somehow.
Now, none of this is particular to Go. Errors are a fact of life and we always need to handle them. In languages with exceptions they can go under the radar since you're not forced to handle them: you can just let them bubble up to the caller, which can lead to an exception blowing up very far from the code that caused it. In Go you're not forced to handle them either, unlike in say Rust or Zig, where you have to explicitly ignore them. Still, the fact that errors get returned from functions makes Go's error handling more explicit than languages with exceptions.
So, what do Go errors look like? First, error is just an interface:
type error interface {
Error() string
}
It's common to define sentinel errors which are effectively just constants, created with errors.New(). One example is the aforementioned ErrNotExist. It can be checked with a direct equality comparison err == ErrNotExist. However it's preferable to check with errors.Is(err, ErrNotExist). This is because of error wrapping. You can wrap an error into another error type by implementing the method Unwrap() error in the wrapping error type.
For example, I could create a type that wraps filesystem errors with some contextual information on where in the program the operation was taking place. With that I lose the ability to check for ErrNotExist through a direct equality comparison, but I can still check for it with errors.Is().
There's also errors.As() which can match an error against a particular error type, as opposed to a particular error value. Also, you can wrap errors on the fly without creating new error types, passing the error fmt.Errorf() and using the %w specifier, like fmt.Errorf("failed to open file: %w", err). This is useful for adding a "stack trace" of sorts to errors while still allowing for checking for them with errors.Is().
Dave Cheney's blog post recommends avoiding sentinel errors, because they become part of your module's public interface and create coupling. He instead advocates for having "opaque" error values that you're not meant to inspect; if you do need inspecting you can instead define an interface and check if the error implements the interface, through interface conversion:
type fileError interface {
IsDatabaseFile() bool
}
func open(name string) (*File, error) {
file, err := Open(name)
if err != nil {
t, ok := err.(fileError)
if ok && t.IsDatabaseFile() {
// handle database file error
}
// ...
}
// ...
}
Since Go's interface are implicit this doesn't create coupling between modules. It's a quirky and unusual-looking solution to me, compared to sentinel errors. But I can see myself being swayed if I ever worked in a large Go codebase.
The blog post was written before error wrapping was added to Go but it does suggest a solution that looks a lot like what eventually made it into the language.
Godot's system for collision detection works pretty well out of the box for floors, walls and ramps, but some additional work is required if you want to keep your characters from getting stuck on small objects on the floor while walking. More importantly you might also want them to be able to walk up stairs without jumping.
There are different ways of getting around it. One is to pretend that your stairs are really ramps. A better solution is to detect that you're trying to walk into a stair step and teleport you up as you move forward. There's actually a node for this (SeparationRayShape3D) in Godot, but instead I want to talk about a more manual and more tweakable solution that I first found in this video but later in other places as well. The video is pretty good but it focuses more on the implementation rather than explanations and I needed to do some thinking and playing around to understand how it works and what the different values do.
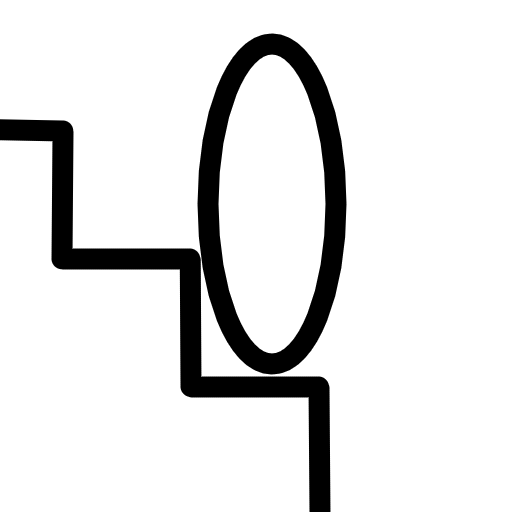
The idea is to continuously run a body motion test to check if stepping forward would lead you to collide with a stair step (or a short object like a small rock). We want to find out how far we'd make if there was no stairs, and then teleport up from that point so that we're right above the stairs.
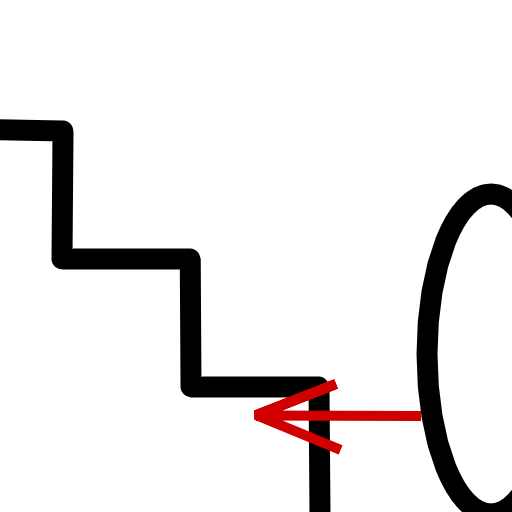
Basically we should move from the situation on the left to the situation on the right above.
Godot has a PhysicsServer3D.body_test_motion() function that we can use to conduct the motion test. It performs the motion and then returns (in the result argument) the point of collision. We can tweak the basic idea above so that the collision point returned is precisely the point we want to teleport to. The strategy is to first move up and then forward (by the amount we would normally move horizontally). This will be the initial position (the from parameter) in the test. Then we move down, by setting the motion parameter to a value that will eventually reach the stair step. If we collide then we know that we are running into a stair step, and we'll also know exactly where we should teleport to.
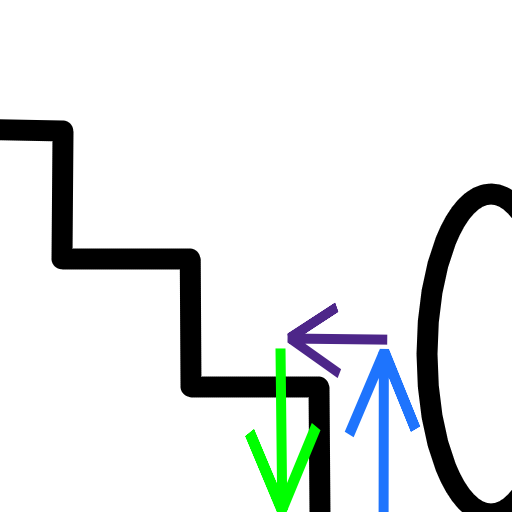
The following poorly made diagram shows the rough idea. (I really should get better at making these sometime.)
The blue arrow will determine the height we're starting the test from, and it should be higher than the step height. The purple arrow is the character's expected movement, assuming there was no stairs here. This will be equal to the horizontal velocity. Blue + purple gives the initial position of the test (i.e. the from parameter). We then move down by the green arrow (the motion parameter), whose length can be equal to the blue arrow.
There are some additional details to pay attention to when implementing this. One is that you have to be careful not to allow moving up stairs that are too tall, otherwise you'll also be able to go up walls and such. So you need to define some maximum height your stair steps are allowed to be. Also, as noted earlier, when moving up it's important to move up above that maximum height, and when performing the test you need to move sufficiently down to make sure you reach the step (otherwise you might not collide even though there's a step below). The video I linked uses 2 * max_step_height for both going up and down, which seems to work well in practice. In the picture above the arrows' lengths are clearly less than 2 * max_step_height, which probably also works OK but there might have some cases I haven't thought of.
The final step is to check that the surface we're teleporting to is not too steep. We could do that by checking the collision normal, but there there's an additional complication. Because the body test motion uses the character's collision shape to detect collision, it can happen that the collision point ends up at the edge of the step instead of on top of it. One way to work around that is to use a RayCast3D node. We can place it at the collision point, then move it up a little bit (by a distance a bit below the raycast's length) and then move it forward a little bit (towards the step). We can then check the collision normal for that and if it's not too steep then we're good. This is just a matter of checking that collision_normal.angle_to(Vector3.UP) <= floor_max_angle.
When working through this I really appreciated being able to change values and see them immediately in the game. This will perhaps become less relevant over time but it's immensely valuable for learning and prototyping.
I've been using Emacs for nearly 20 years now, but I still suck at writing elisp. I've never made an effort to learn it seriously and that's something I'd like to start correcting in the near future. I have some ideas. I have an ever-growing collection of scripts I use at work to make several minor tasks less painful, mostly having to do with checking on various AWS resources and updating entries in AirTable. Can I learn enough elisp to move these tools into Emacs, maybe leveraging tabulated-list-mode and/or transient? Who knows. The scripts will probably stay for a while but this could be a fun exercise.
I have a hard time navigating the documentation. I don't have much to complain about - the only specific complaint I have is that it sorely lacks examples - but it just doesn't feel like a good place to hang around. I don't know, it just feels old? The terminology is strange and foreign to me (even after 20 years of Emacs), and basic functions feel underpowered and limited. For example just today I learned about pcase. It is actually a very powerful construct; you can even use it to destructure forms. But I really wish you could destructure objects instead (so I could deconstruct an alist, for example). This is one of the many examples that make me wish I was writing something more modern and cohesive like Clojure.
Of course there are certainly packages that provide structures with better ergonomics but to be honest I don't even know where to look. Like other Lisps, Elisp is extremely extensible but also like other Lisps it suffers from a certain degree of fragmentation, and perhaps due to its age there's likely a reluctance to "modernize" things when there's so much history behind it. At any rate, there's a lot of nice modern packages around (I've been using kubel as inspiration for my AWS exercise) so even if the documentation is uncomfortable to me there's plenty of source code to read. Hopefully I'll be able to move my little projects forward and learn some more of the editor I've been using for most of my life on the way.
It turns out that Godot's "Y is positive" convention originates in OpenGL, which follows the same convention.
I also learned that Direct3D uses a left-handed coordinate system (while still having y pointing up). It's weird but it also means that if you go forward you move in the positive Z direction, whereas in Godot you go negative. (The camera will point in the positive Z direction by default though.)
Finally, I enjoyed seeing Euler getting roasted in the Godot docs:
This way of representing 3D rotations was groundbreaking at the time, but it has several shortcomings when used in game development (which is to be expected from a guy with a funny hat).
I like this notion of having one of the most important mathematicians of all time be just a guy with a funny hat who came up with a system for rotations that happens to be not very good for games.
Ever since I first heard about Go (before it even came out, I believe) I was very dismissive. It was a language for old crufty programmers who mainly wanted a slightly nicer C, ignoring all recent developments in language design. The future was in languages with super advanced compilers like Haskell. For people who couldn't handle Haskell there was always OCaml.
This was before I had any kind of software development job though, and since then I've been learning to appreciate the value of incremental changes as opposed to introducing a paradigm shift. Haskell and OCaml aren't much more popular than they were back in 2008 but a lot of ideas from functional programming and the Hindley-Miller type system have become more mainstream.
Go eschews even those developments but it's still doing fine. At least for the type of work that I tend to, which is mostly web servers. I might be missing some of the history here, but Go seems to have avoided the framework and library churn that I've observed throughout my career. Is it because a lot of the stuff you might need for a web server is already built-in, and most of it has been there from the start? But Python also has a lot built-in and it still went through a fair amount of churn. Maybe it's because people who are comfortable writing if (err != nil) { return nil, err } are also not the kind of people to pursue the new hotness all the time.
Anyway, I've been writing and reading some Go for work and it's been good. Interfaces are pretty nice. I don't know yet whether I prefer them to Rust's traits, but so far I like that they're implicit. Writing an HTTP server is a simple matter of implementing a ServeHTTP(http.ResponseWriter, *http.Request) method on a type. This will automatically make the type implement the Handler interface, meaning I can just pass it to http.ListenAndServe(). It's pretty sweet.